이 글은 제 주관이 많이 들어있고 팩트와 다를 수 있습니다. 지적해주시면 고치겠습니다.
회사에서 신규 프로젝트에 포트 앤 어댑터 패턴을 도입하기로 했다. 헥사고날 아키텍처보다 포트 앤 어댑터 패턴이라는 말이 더 명료하게 이 패턴을 설명하는 것 같다. 어쨌든 공부할 시간이 많지는 않았고 짧게 공부한 기록을 남겨본다.
포트 앤 어댑터 패턴에 대해 이야기하기 전에 전통적(?)인 레이어드 아키텍처를 먼저 짚고 넘어가야 할 것 같다.
레이어드 아키텍처는 프레젠테이션, 도메인, 영속 세 개의 계층으로 이루어진 아키텍처다.
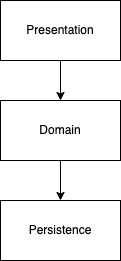
프레젠테이션 계층은 HTTP 요청을 처리한다. 도메인 계층은 비즈니스 로직을 담당하는 가장 핵심 레이어다. 마지막으로 영속 계층은 데이터 영속화를 담당한다.
레이어드 아키텍처의 규칙은 간단하다.
- 의존성은 한 방향으로만 흐른다.
- 계층을 건너뛰지 않는다. 즉, 프레젠테이션 계층에서 바로 영속 계층으로 넘어가지 않는다.(또는 그 반대)
이것은 규칙이긴 하지만 강제되지는 않는다. 흔히 영속 계층에 있는 JPA 개체(entity)를 프레젠테이션 영역까지 반환하는 코드를 곳곳에서 볼 수 있다. 소규모 프로젝트에서야 괜찮을지 모르지만 시간이 지나면 프로젝트는 커지고 점점 어디가 어디인지 알 수 없게 된다. 함께 개발하는 사람이 많아질수록 코드는 꼬일 것이다. 어떤 사람은 도메인 레이어에서 비즈니스 로직을 작성하겠지만, 어떤 사람은 도메인과 도메인의 의존성을 끊겠다고 프레젠테이션 레이어에 A서비스를 호출한 결과를 B서비스에 넘기는 중요한 비즈니스 로직 순서를 관장하기도 한다. A를 호출한 다음 B를 호출하는 게 뭐가 어떻느냐고 할 수 있지만 이것은 중요한 비즈니스 로직의 일부다. 비즈니스의 순서를 프레젠테이션 레이어가 알고 있다는 것은 레이어의 책임을 위빈하는 일이다.
레이어드 아키텍처의 가장 큰 문제점은 데이터베이스 드리븐 개발을 유도한다는 점이다. 보통 Java/Spring으로 개발하면 JPA를 통해 영속 계층을 구현한다. 이럴 경우 도메인 계층과 영속 계층이 강결합된다. 왜? 이런 예시를 들어볼 수도 있을 것 같다.
// domain layer
class PostService(
private val postRepository: PostRepository
) {
fun postUpdate(PostUpdateReq req) {
val post = postRepository.findByIdOrNull(req.id)
?: throw PostNotFoundException(req.postId)
//영속 계층의 JPA 엔티티를 불러와서 content 수정 메소드를 호출
post.updateContent(req.content)
}
}
// persistence layer
@Entity
class Post {
var content: String = ""
// 도메인 레이어로부터 content를 받아서 수정
fun updateContent(content: String) {
this.content = content
}
}도메인 계층에 있는 게시물 본문을 수정하는 로직이다. 영속 계층과 매우 강결합되어 있고 비즈니스 로직이 레이어에 걸쳐 분산되어 있다.
- 도메인 계층은 영속 계층에서 Post를 조회해온다.
- 영속 계층의 content를 새로운 content로 바꾸라는 커맨드 메소드를 호출한다.
- 영속 계층의 Post 객체는 content를 인자로 받아서 본문 내용을 갱신한다.
영속 계층은 비즈니스 로직을 처리하는 영역이 아니다. 이 코드는 도메인 레이어의 응집도가 낮고, 책임이 여러 레이어로 분산됐다. 레이어드 아키텍처 원칙을 지키고 있다고 할 수도 없다.
이런 식으로 코드를 작성하면 가장 중요하고 보호받아야 할 도메인 레이어에 대한 테스트도 어려워진다. 또한 개발 시작부터 JPA 관련된 설정에 신경써야 하기 때문에 계속 JPA와 엮어서 도메인 영역을 생각할 수밖에 없다. 그러다보면 도메인 == JPA 엔티티라는 착각에 빠진다.
그럼 도메인 계층과 영속 계층을 확실하게 분리해보면 어떨까?
// domain layer
class PostService(
private val postRepository: PostRepository
) {
fun postUpdate(PostUpdateReq req) {
val postEntity = postRepository.findByIdOrNull(req.id)
?: throw PostNotFoundException(req.postId)
val post = Post.of(postEntity)
//영속 계층의 JPA 엔티티를 불러와서 content 수정 메소드를 호출
post.updateContent(req.content)
// 비즈니스 로직은 도메인 레이어의 Post에서 처리하고
// 영속 계층은 update 쿼리만 날리도록 한다.
postRepository.update(post.toJpaEntity())
}
}
// 도메인 계층의 Post 클래스
class Post {}
// 영속 계층의 PostJpaEntity클래스
@Entity
@Table(name="post")
class PostJpaEntity {}
@Repository
class PostRepository(
private val postJpaRepository: PostRepository
) {
fun findByIdOrNull(id: Long) {
// find post...
}
fun update(post: PostJpaEntity) {
// update...
}
}직접적으로 JPARepository를 상속받는 PostRepository를 의존할 때보다는 덜 의존적일 수도 있으나, 여전히 의존적이기는 마찬가지다. 영속 계층의 변경에 도메인 로직이 영향을 받야아 할까? 그럴 이유가 없다. 파일 시스템에 저장하든, 데이터베이스에 저장하든, 캐시에 저장하든 도메인 로직은 달라지지 않는다. 이것이 레이어드 아키텍처의 한계다.
레이어드 아키텍처가 무작정 <나쁘다>는 의미가 아니다. 대규모 프로젝트에서도 여전히 레이어드 아키텍처는 유효하다. 어쩌면 그것만으로 충분한지도 모르겠다. 굳이 먼길을 가지 않더라도 약간의 우회만으로 한계를 보완해서 쓰는 팀도 분명히 있을 것이다. 하지만 어쩄든 Ports and adapter 또는 헥사고날이라고 하는 아키텍처가 이 레이어드 아키텍처의 한계를 극복할 수 있다고 주장하고 있다. 그리고 따지고 보면 이 길이 그다지 먼길도 아니다.
ports and adapter 패턴 또는 헥사고날 아키텍처는 도메인 로직을 가장 안쪽에 두고 보호한다. 도메인 로직은 외부로 향하는 의존성을 가지지 않는다. 이렇게 하는 방법은 의외로 간단하다. 의존성 역전이다. 헥사고날, 육각형이라는 의미는 다방면으로 확장해서 사용할 수 있다는 의미로 이름지어졌다는데, 개인적으로는 ports and adapter 패턴이라는 말이 더 직관적이고 이해하기 쉬운 것 같다.
ports and adapter 컨셉은 간단하다.
(도메인 바깥에서)어댑터를 만들어서 (도메인 내부의) 포트에 꽂아라.

Ports and adapter를 검색하면 이런 다이어그램을 찾아볼 수 있다.
Port는 in port와 out port로 나눈다. 나누는 기준도 명료하다.
- in port
- 외부에서 domain을 사용하는 adapter가 구현해야 하는 포트
- out port
- domain이 영속 계층 같은 외부 모듈을 사용해야 할 때 만드는 포트.
- 외부 영속 모듈은 out port를 구현하지만, 도메인 모듈은 Port에만 의존하기 때문에 어디서 어떤 구현체가 들어오는지 알 수 없다.
그리고 UseCase.
UseCase는 말 그대로 유즈케이스를 담은 인터페이스다. 이를 테면 게시물을 수정한다고 하면 게시물을 수정하는 유즈케이스 메소드가 하나 있는 것이다.
interface PostUpdateUseCase {
fun update(PostUpdateCommand command)
}실제 비즈니스 로직은 이 유즈케이스를 구현해서 만든다.
// domain
class PostUpdateService(
private val postFindPort: PostFindPort,
private val postUpdatePort: PostUpdatePort,
): PostUpdateUseCase {
override fun update(PostUpdateCommand command) {
// post는 JPA 엔티티가 아니라 도메인 모듈의 POJO 엔티티임.
val post = postFindPort.find(command.id)
// 업데이트
post.updateContent(command.content)
//port의 update()를 호출.
//UpdatePort의 구현은 런타임에 결정되고, 도메인은 알 수 없음.
postUpdatePort.update(post)
}
}위 도메인 로직을 호출하는 in adapter를 간단하게 만들어보면 이렇다.
// web 계층
class PostUpdateController(
private val postUpdateUseCase: PostUpdateUseCase
) {
@PutMapping("/post")
fun updatePost(String content) {
// 도메인 레이어의 UseCase를 호출한다. 구현체는 알 수 없음.
// 그냥 UseCase 인터페이스에 해야 할 일을 위임.
postUpdateUseCase.update(PostUpdateCommand.of(content))
}
}
out port를 구현하는 영속 계층을 간단하게 만들면 이렇다.
// 도메인 계층의 Port Interface
public interface PostUpdatePort {
fun updateContent(post: Post)
}
// 영속 계층. 도메인 계층은 해당 계층이 있는지도 모름.
class PostUpdateAdapter(
private val postRepository: PostJpaRepository
): PostUpdatePort { //도메인 계층의 PostUpdatePort를 구현함
override fun updateContent(post: Post) {
val postJpaEntity = PostJpaEntity.of(post)
postRepository.save(postJpaEntity)
}
}이런 식으로 Ports and adapter 패턴을 사용해서 외부로부터 도메인 계층을 보호하는 프로젝트를 구성할 수 있다. 만약 JPA가 아니라 다른 ORM 또는 SQL Mapper로 변경한다던가, 데이터베이스 자체를 바꾼다던가 혹은 저장소를 캐시로 바꾼다고 하더라도 out port만 구현한다면 도메인 로직은 그대로다. 마찬가지로 Web 요청이 아니라 배치 시스템이나 그외 다른 시스템에서도 마찬가지로 in Port만 구현한다면 도메인 로직을 그대로 사용할 수 있다. 책임이 잘게 나눠지기 때문에 유지보수도 쉬워진다. 거대한 PostService에서 작업해야 할 곳을 찾는 것보다 비즈니스 로직을 구현한 클래스가 들어있는 service 패키지의 UpdatePostService에서 작업해야 할 곳을 찾는 것이 훨씬 빠르고 수월할 것이다. 이것이 클린 아키텍처, 헥사고날 아키텍처, 포트 앤 어댑터 패턴을 이야기하는 사람들이 말하는 이 아키텍처의 장점이다.
그런 단점은? 소스코드가 늘어나고 패키지, 클래스의 개수는 더 늘어난다(고 한다).
아직은 진짜 이 패턴의 단점이 무엇인지 모르겠다. 아직은 이론만 공부하고 간단한 샘플 코드만 만들어봐서 간단하고 명료한 규칙으로 꽤 괜찮은 아키텍처를 구성할 수 있는 실버불릿처럼 느껴진다. 앞으로 실제 프로젝트에 적용해보면서 단점이나 애매한 점을 기록하고 몇 달 뒤에 다시 한 번 여기에 대해 쓰겠다.
이 글을 작성하면서 참고한 책과 영상과 뭐 등등
- 만들면서 배우는 클린 아키텍처(만배클아)/위키북스 톰 홈버그 저, 박소은 옮김
- https://github.com/wikibook/clean-architecture
- [NHN FORWARD 22] 클린 아키텍처 애매한 부분 정해 드립니다.
- 클린아키텍처는 죽었다! 헥사고날 아키텍처 10분만에 대충 이해시켜 드림 | Hexagonal architecture
'Study' 카테고리의 다른 글
| k-NN과 ANN (0) | 2025.05.08 |
|---|---|
| shared lock, exclusive lock (0) | 2022.08.15 |
| LearingSQL #4,5,6 (0) | 2022.06.02 |
| type check는 왜 필요한가? (0) | 2022.05.18 |
| 테스트 대역 (0) | 2021.12.21 |